고정 헤더 영역

상세 컨텐츠
본문 제목
Stock Market Prediction on High-Frequency Data Using Generative Adversarial Nets 논문 리뷰
본문
https://downloads.hindawi.com/journals/mpe/2018/4907423.pdf?ref=https://codemonkey.link
Stock Market Prediction on High-Frequency Data Using Generative Adversarial Nets라는 논문을 리뷰하는 글입니다.
Papaer Point
이 논문의 특징은 다음과 같습니다.
- generator는 LSTM으로 disriminator는 CNN을 사용
- 기존의 Stock prediction에서는 사용하지 않았던 GAN 모델을 사용했다.
- 2018년도 기준 (논문 작성일 기준)
- GAN을 이용하게 되면 복잡한 재무적 지식과 어려운 기술 분석을 피할 수 있게 해 준다는 장점을 가짐
- 이미지 처리에서 많이 사용하는 그 GAN(Generative adversarial network) 맞음
- 종가를 예측하는 식으로 모델을 구성
- High Frequency Data로 예측 (몇 초 정도의 frequency를 가진)
Model
Model에 대한 설명을 이어가 보도록 하겠습니다.
논문에서 제시하는 모델을 One step 만큼 진행된 값을 예측합니다. 논문에서 제시하는 Prediction Model은 다음과 같습니다.

X는 인풋을 표현하고 1부터 T까지의 time step을 의미합니다. 그리고 다음과 같은 indicator들을 prediction에 사용합니다.
- Opening price
- Maximum price
- Minimum price
- Trading volume
- Turnover Bias
- Bollinger bands
- Directional movement index
- Exponential moving averages
- Stochastic index
- Moving averages
- MACD (Moving Average Convergence & Divergence)
- Relative strength index
G는 LSTM으로 만들어진 Generator입니다.
D는 CNN으로 구성되어있는 Discriminative model으로 1부터 T까지의 시점 주가와 T+1 시점의 주가가 Input으로 들어올 때 , 주가가 실제 주가(Real data)인지 아니면 Generative model에서 만들어낸 주가(Generative model data)인지 맞추는 역할을 합니다. 즉 해당 모델도 이미지를 도메인으로 쓰는 GAN과 유사하게 Generator와 Discriminator를 번갈아가면서 훈련을 시킵니다.
GAN은 사실 다른 GAN들과 크게 다르지 않습니다만 Loss는 조금 차이점이 있습니다.
이 모델은 loss function을 다음과 같은 단계를 거쳐서 계산합니다.
1. sigmoid cross-entropy loss

- cross entropy loss를 이용하여 만들어진 주가(fake data)와 실제 주가(real data)의 loss를 구합니다.
2. the generative model G ought to decrease the forecast error loss; that is, L_P loss라고 논문에서는 설명하고 있습니다. L1, L2 distance를 이용하여 주가(fake data)와 실제 주가(real data)의 loss를 구합니다.

3. T+1 시기와 T시기의 loss를 이용하여 주가(fake data)와 실제 주가(real data)의 loss를 구합니다. 이 loss가 논문에서 제시한 loss이기 때문에 기존의 GAN에서 사용하는 loss와 차이가 있습니다. 여기서 사용되는 부호 함수 (sgn)는 기준점보다 크면 1 작으면 -1로 판별해주는 함수입니다.

4. 앞서 말씀드린 1,2,3 로스를 전부 더해줘서 Generator의 loss를 구합니다.

5. 이 부분은 일반적인 GAN과 유사합니다. Discriminative model이 실제 주가를 Y 값으로 입력받으면 True, fake data를 Y값으로 입력받으면 False

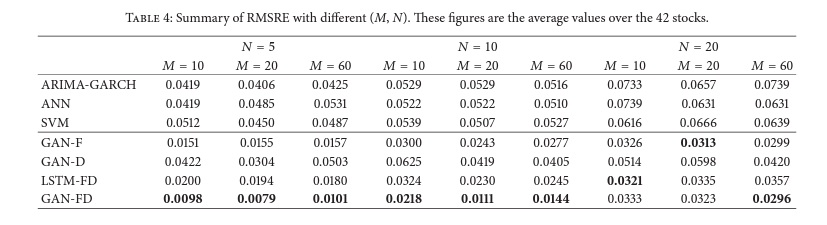
Result
실험 결과 GAN-FD가 가장 좋은 결과를 보였다는 실험 결과를 얻었습니다.